
source: EDN article
Jeff Smoot, VP of Application Engineering at CUI -June 08, 2016
You know how it is … you learned all this detail about electronics back in college and yes, you understood it then, but unless you’re using it day in and day out, that knowledge can fade and casual usage can erode the real meaning.
The classic example I keep coming across is the confusion between accuracy and resolution. Although not wishing to get into a lengthy explanation here, put simply, resolution is how finely we can divide a measurement, which could be the divisions on a ruler or the number of decimal places we use to express a result, whereas accuracy is how close that reading is to the true value.
Appreciating this distinction is important – after all, while it may be of interest to observe the display on the fuel pump when filling your car, what matters at the end of the day is that the price you pay is for the true volume that has been dispensed. Terms like ‘reliability’ and ‘MTBF’ (mean time between failures) are similarly discussed with casual disregard to what is really meant. The trap many people fall into is wrongly assuming that the MTBF figure equates to the expected life of a product.
So, with that cautionary note in mind, I felt a brief refresher about the basics of reliability would seem to be in order. This will inevitably entail some back-to-basics theory but I’ll attempt to keep it as easy to follow as possible – for anyone wanting to delve deeper there are plenty of online resources although naturally I’m going to recommend an application note that can be found on CUI.com.
The word ‘reliable’ is used in many spheres of life and synonyms include dependable, trustworthy and unfailing. These words can be used about people or things but when applied to things, especially manufactured products, there is a slight mind-shift as we think more in terms of ‘how reliable’ something is or for how long we can reasonably expect to depend on it. This leads us to a quite simple definition, which is that:
Reliability is the probability that an individual unit of a product, operating under specified conditions, will work correctly for a specified period of time.
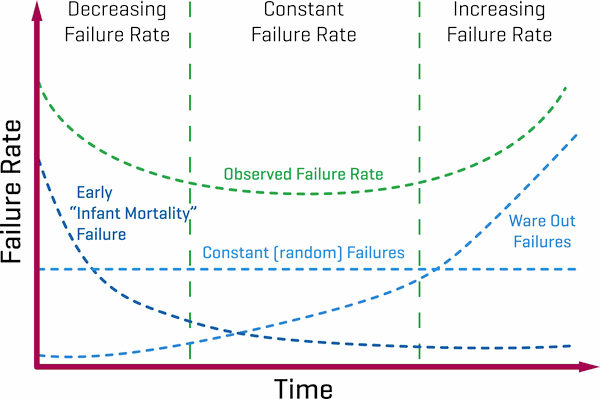
This naturally leads us to thinking about when the product stops working, i.e., when it fails for whatever reason. Product failures can occur at any time but they are not totally random. This is why, if you measure the individual lifetime for a large enough sample of products, you will typically get the classic “bathtub” result when plotting failure rate against time. The reason for this is that products experience early life “infant mortality” and they also wear out as they age. These characteristics overlay the constant level of failures to produce the observed failure rate shown in the chart below.


Classic “bathtub” curve of observed failure rate over time
What we really want, though, is to get a better handle on how reliable our product ought to be. So, armed with our failure rate data, the intrinsic failure rate of the product is defined as the failure rate during the constant part of its life cycle. This we denote as λ, from which the expression for reliability, denoted R(t), over time t, is given as:
R(t) = e -λt
Taking the inverse of failure rate, 1/ λ , we also get the mean time to failure (MTTF) or the slightly less correct but more commonly used term MTBF (mean time between failures). Plotting reliability against MTTF, as shown in the second chart, then provides us with some interesting insights:

A product whose intrinsic failure rate is 1 in a million (i.e. 10 -6) failures per hour has, by definition, an MTBF of one million hours. However the probability of it lasting 1 million hours (i.e. x=1 on the graph) is just 36.7%, which pretty much scotches any false assumption that MTBF equates to expected life. Indeed, further inspection of the graph shows that the probability of surviving more than 500,000 hours is only just over 60%, while a more respectable 90% reliability figure only equates to 100,000 hours.
All this serves to emphasize the importance of treating data such as MTBF with caution. Also, for most real products, it is important to understand where this data actually comes from. The bathtub curve discussion above assumes data collected from a large sample of products over a long time but this isn’t generally a practical approach. Instead calculating the failure rate for an end product depends on predictions that are based on one of a number of standardized component databases, which in turn have derived data using various sources including laboratory tests, burn-in results and field tests.
It should also be appreciated that for any product built from multiple components, such as a power supply, the failure rates for all these components must be summed together, resulting in an overall lower MTBF. This also reveals that the overall reliability of a system can be no better than its least reliable component, and while this may seem a fairly obvious conclusion, it also certainly suggests that a designer should pay most attention to improving the reliability of the weakest components.
Returning to my opening scenario of filling your car with fuel, recognizing the importance of accuracy when paying for something by volume, weight or whatever, is like realizing that that figures for a product’s reliability or MTBF don’t guarantee life expectancy any more than the result of a medical checkup. Instead these figures are perhaps more useful in providing a consistent approach for comparing products, either within a vendor’s range or from one vendor to the next.

