

This blog post was written by Philip Lessner, Chief Technology Officer at YAGEO Group and posted on his LinkedIn profile AI – Why Now?.
The latest AI tools can answer your questions, generate an image from a text description, and even make a video for you. The progress in the last couple of year seems amazing. It’s almost magical what’s happening. But, why now? The answer is the convergence of three elements:
- Algorithms
- Data
- Processing Power
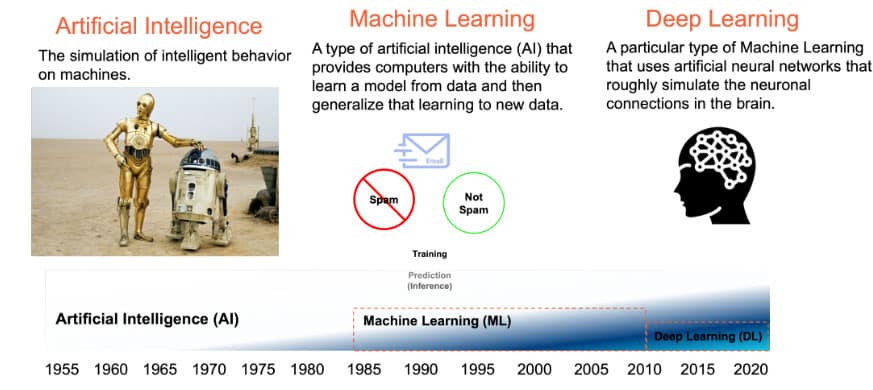
Before we examine these in more detail to see how they contribute to the current “AI Revolution”, let’s first define what AI is (Figure 1).
AI is the simulation of intelligent behavior of machines and the concept has been around since mid-last century.
Machine learning is one way to practically approach the goals of AI. In classic programming, the data is fed through a series of steps that are predetermined by the programmer. In machine learning, the data is used to train a model to recognize patterns in the data, and then this model is applied to new data to make predictions. One of the oldest uses of machine learning is spam prediction. The model is trained on data labeled Spam or Not Spam and then when a new email is fed to the model, it classifies it as Spam or Not Spam. This prediction step is called inference.
There are many machine learning algorithms, but the most powerful ones that have been applied are called ‘Deep Learning’. These are based on algorithms that mimic the structure of the brain, so they are also called neural networks.
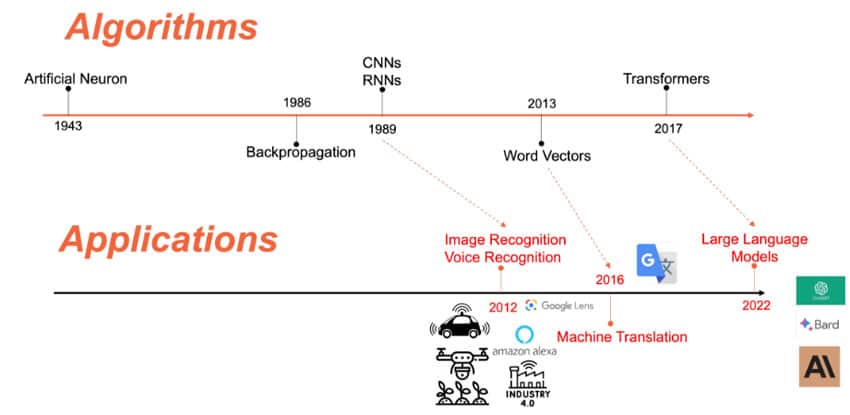
The artificial neuron was first proposed in 1943 (Figure 2), but for a long time no one knew the algorithm for using data to determine the parameters of a neural network—called “training” the neural network. The breakthrough came in 1986 when Geoffrey Hinton and his colleagues at the University of Toronto discovered a technique called backpropagation that allowed training of neural networks.
In the late 1980’s two types of neural networks were discovered that allowed efficient recognition of images and voice—Convolutional Neural Networks and Recurrent Neural Networks. However, it wasn’t till 23 years later that these were widely applied in apps like Amazon Alexa, Apple Siri, and Google Lens and industrial applications like automated optical inspection (which is used in YAGEO factories). These types of networks also find use in emerging applications like precision agriculture and image recognition in autonomous vehicles.
In 2013 Tomas Mikelov and his colleagues at Google determined how to represent words and sentences as mathematical vectors, and more importantly, how to make using them practical in machine learning models. This did for natural language processing what CNNs and RNNs did for image recognition. Three years later, this was applied to Google Translate which improved the quality of machine translation by orders of magnitude.
In 2017 this was extended by another type of neural network called Transformers which lead to so called Large Language Models (or LLMs) the most famous of which is ChatGPT released 5 years later in 2022.
Why the lag between the development of the algorithms and the commercial release of these products?
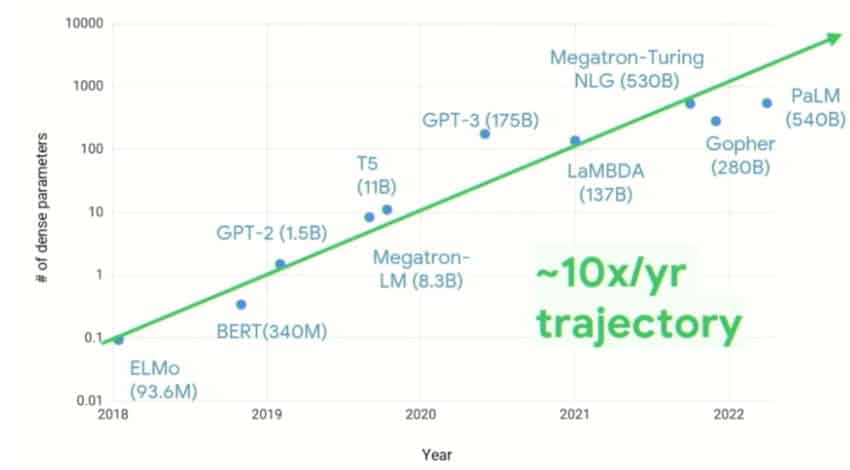
It turns out that you need a lot of data to train these algorithms. The neural network models have millions or billions of parameters and the number of parameters is growing by 10x per year (see Figure 3). It takes millions of images and billions of words to properly train these models.
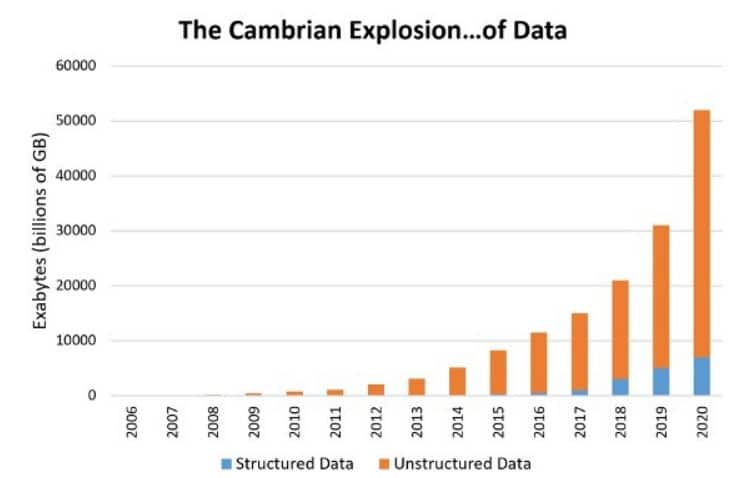
This was really enabled by the growth of internet when millions of images and billions of words of text became readily available. This is represented by ‘unstructured data’ in the graph in Figure 4.
In addition to the math (algorithms) and the data you also need lots of computational power to train and deploy these models with billions of parameters. By the mid 2000’s computational power had advanced enough to begin to run these deep learning models (Figure 5). The real advance that gave enough computational power was the development of the GPU or graphics processing unit. These are able to process many operations in parallel and the operations they are optimized for in graphics are of a similar form to those needed for deep learning. Now there are also dedicated chips that are, in some cases, even faster than GPUs to process the data.
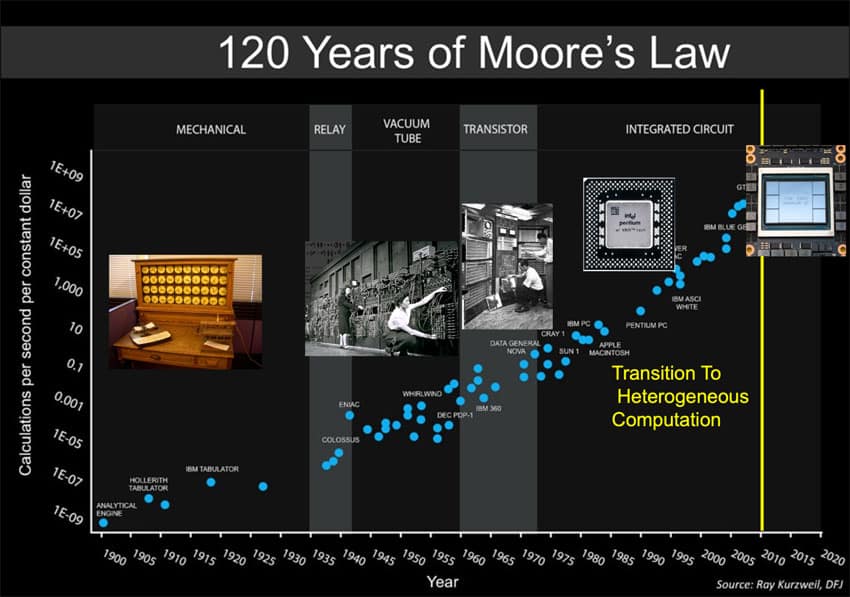
So here we are in 2024 able to to access all these amazing applications because of the convergence of algorithms, data, and computational power over the last 80 years.
Storm clouds on the horizon, however. Compute takes power (and energy) and the amount of power needed may soon outstrip the ability to supply it. In the next chapter we’ll take a deeper dive into this problem and then look at what’s being done to address it.
Powering AI in the Data Center
Increasing computational power was one of the contributors to the current ‘AI moment’. Those advances in computational power come at the cost of larger and growing power loads and energy use. The energy used by AI could become a limiting factor in the growth of this amazing technology.
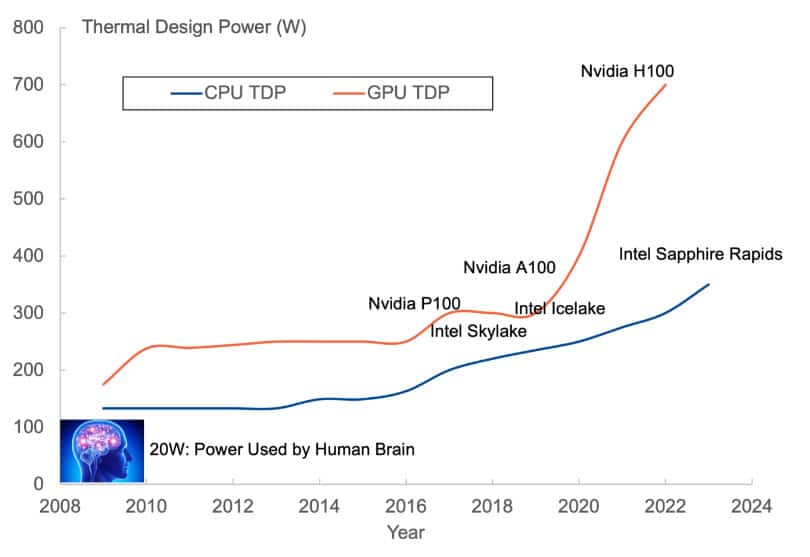
Fifteen years ago, CPUs and GPUs designed for servers only operated at a couple of hundred watts. Figure 6. shows how the Thermal Design Power (TDP) of CPUs and GPUs has evolved over time. Now the most advanced GPU like the Nvidia H100 used to train LLMs has a TDP of 700W and the next generation of processors will exceed 1kW. For reference, the human brain, a highly efficient organ, only uses about 20W of power. The key point is that this won’t be tied to just one customer. It is not just Nvidia, growth will also be driven by Amazon, META, and Google.
Training and deploying these cutting edge generative AI models is very energy intensive as many CPUs and GPUs need to work in parallel. (10,000 GPUs working together during a training run is typical). ChatGPT or AI-powered search uses 6 to 10 times the energy of a standard Google search[1].
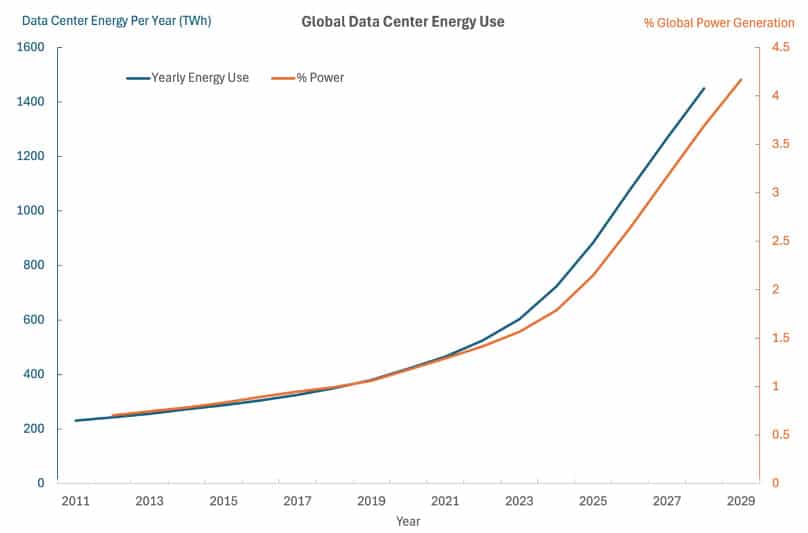
Over millions or billions of users all this energy adds up. Currently, data centers use about 1.5% of global energy, and in the United States, it’s an even higher 4%. The percent energy used by data centers has been growing, but as Figure 7. shows the deployment of AI and particularly generative AI starting in 2023 may cause a rapid increase in the rate of growth of energy use which could reach more than 4% of global energy by the end of the decade. This has stoked the fear that power generation may become a limiting factor in the rate of AI advancement and has motivated large players like Meta, Microsoft, Google, Amazon, etc. to conclude that traditional green energy sources like wind and solar may not be enough and other sources like nuclear power need to be brought into the mix [3].
Can we slow down this growth in energy use? Yes we can. The four main components that can influence energy use are:
- Software Algorithms
- Custom Processors (ASICs)
- Thermal Management
- Power Management
New software algorithms that make more efficient use of compute are being released often. For example, model quantization or the use of lower precision numbers to represent the parameters of the model saves energy because a large part of the energy used is moving parameters from memory to the CPU/GPU. New model architectures that require less computational power are being introduced. There is also the realization that for some tasks, models can use a smaller number of parameters saving on both the energy used during training and also during inference.
The transition from CPU-based compute to heterogeneous computation based on CPU+GPU processing resulted in large energy savings because the parallel nature of GPU computation is well suited to neural network computations. Purpose-build ASICs can improve efficiency even further. Google released its TPU (or Tensor Processing Unit) about a decade ago in order to power the first generation of AI-enabled Google Translate. Processors like the TPU (now in its 5th generation) and others from a growing list of companies are optimized in hardware for operations like matrix multiplication that are fundamental building blocks of deep learning algorithms.
A significant amount of data center energy use is for cooling and other non-compute uses (lighting, etc.). The PUE metric is the ratio of total energy used by the data center to energy used for compute. Ideally, this is 1, but in practice it ranges from about 1.1 to 1.4. That means that 10% to 40% of the energy used by the data center is not used by compute. Most of that energy is used to cool heat produced by components which are the processors and also the supporting passive components.
That brings us to the important topic of power management which has a direct bearing on thermal management and other power losses. Many technologies are being introduced to reduce power losses in the data center. These include:
- New power supply topologies
- Transition from 12V to 48V power distribution
- Wide band gap (i.e., GaN, SiC) power switches
- Low loss passive components
- Moving the power supply closer to the chip (vertical power delivery, embedded components)
Traditional buck and boost convertors are extensively used in power delivery, but new specialized topologies such as LLC and STC [4] have begun to be deployed. These new topologies can offer higher efficiency and, in some cases, reduced component count.
Power losses in wiring are proportional to I²R. Reducing the current reduces the power loss. One way to do that is to increase the voltage. Data centers have begun to replace 12V power buses with 48V power buses which can lower the power losses in the wiring by the square of the ratio of voltages or 16x.
Wide band gap semiconductor power switches are capable of operating at higher temperatures, higher voltages, and higher frequencies than traditional silicon-based semiconductors. Cooling requirements can be reduced and passive component size can be reduced offering the opportunity to move them closer to the processor and, thereby, reducing losses in the circuit board wiring.
Significant amounts of power are dissipated in due to the ESR (Equivalent Series Resistance) of capacitors and losses in the windings and magnetic cores of inductors. These losses eventually are eliminated as heat. So reducing these so called ‘parasitic losses’ can reduce wasted energy and also reduce cooling requirements.
Moving the power supply components (PMIC, passives) closer to the processor chip reduces resistive and inductive losses between the supply and the processor chip. This reduces parasitic power losses and also provides for better voltage control at the chip under high current load transients which are present in high performance processors.
These new power technologies require us to develop new components to meet the new voltage, frequency, size, and efficiency requirements needed to power the AI data center.
Passive Components for AI
The previous chapter we argued that Generative AI could lead to energy consumed by data centers growing from ~1.5% of the worlds energy use to over 4% by the end of the decade, but that there were several approaches which could slow down this rate of growth. One of those areas is advances in power distribution and conversion in the data center. New advanced passive components are enabling the new power conversion paradigms in the modern data center designed for AI applications.
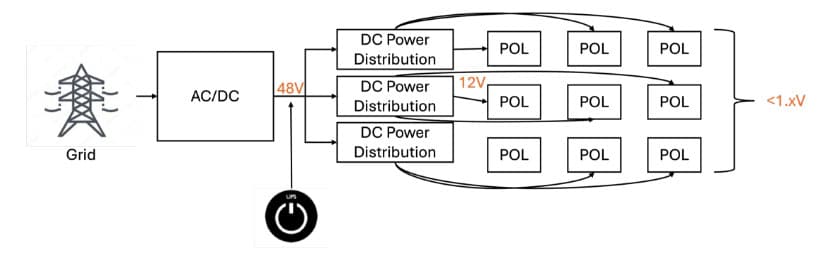
Figure 8. shows a schematic of power distribution in the data center. AC power from the grid is first converted into an intermediate DC voltage. Traditionally, this was 12V, but the trend has been to move this up to 48V to lower the current, and, therefore, reduce the power losses in the wiring. The power is distributed throughout the data center and into the individual racks via this 48V system. The 48V buss is further stepped down to 12V at the motherboard and finally at point of load (POL) stepped down again to the 1.xV core voltages required by the processors. Not shown in the figure are other voltage rails that power memory and networking sub-systems.
A significant amount of motherboard area is consumed by power conversion components. Figure 9. shows the front side and back side of a board containing an Nvidia H100 processor. Outlined in yellow on the front side is power and in green the GPU and high bandwidth memory. The majority of the area on the front side is taken up by inductors and Aluminum and Tantalum Polymer capacitors while the backside area is dominated by MLCCs with some Polymer capacitors present also.

Capacitors
Although –48V rails have been used in telecom equipment for years, 48V rails are new for data centers and are now also being considered for automotive applications. The increased rail voltage requires higher voltage capacitors, 50V for Class I MLCC ceramic capacitors and 63/75V for Aluminum capacitors and Tantalum polymer capacitors, to be used in the various converter topologies depending on capacitance and ESR requirements.
The U2J dielectric is a Class I MLCC dielectric with about 2.5x the capacitance of C0G, but also with stable temperature and voltage characteristics. MLCCs based on this dielectric are useful in power applications where high ripple current handling capability and stable characteristics are needed. To provide higher capacitance, the capacitors can be stacked, and YAGEO Group has developed a technology, KONNEKT™ that allows stacking while still retaining the ability to surface mount the capacitors using a Pb-free reflow process. U2J capacitors can be connected and mounted to the board rotated 90° which gives much lower ESR and ESL than a vertical stack. This U2J/KONNEKT™capacitor stack has been incorporated by Google into the their Switch Tank 48V Converter (STC) which has a higher efficiency than traditional topologies.
Tantalum and Aluminum Polymer capacitors as well as traditional wet Aluminum Electrolytic capacitors are all used in bulk decoupling and filtering applications. These are now available in 63 and 75V rating that are compatible with 48V voltage rails.
At the motherboard level, the 48V power is converted to 12V as an intermediate bus voltage. 16, 20, or 25V Tantalum or Aluminum Polymer capacitors are the appropriate choice for many filtering and decoupling applications and the Tantalum and Aluminum Polymer and Hybrid capacitors are also available in these voltage ratings.
The final stage of conversion is to the 1.xV or less required at the processor. Due to the large current and tight voltage control, the capacitors used in this final stage need to have very low ESR. Yageo AO-Cap offering is a special type of Aluminum Polymer capacitor that achieves very low ESR. The low ESR is achieved by stacking multiple thin elements in parallel. The A700 series stacks these elements on a lead frame while the A720 series doesn’t use a lead frame and is capable of higher capacitances and lower ESR in the same package size.
Data centers operate 24/7 and high power CPUs and GPUs can run at temperatures approaching 90°C. Reliability of components is becoming a key consideration because failure of a board can be very costly especially during an AI training run which can cost upward of 1M USD. YAGEO Group has many component series with long operational lifetimes. An example of this is the A798 AO-Cap series which includes components with 125°C/3000h lifetimes and a soon to be released 5500h lifetime in addition to enhanced humidity performance. Since these very low ESR capacitors are close to the processor, this enhanced life performance is especially critical.
Another critical part of the data center is mass data storage. The trend is towards increasing use of solid state drives (SSDs). SSDs used in enterprise settings include ‘last-gasp’ power backup because loss of data in the case of a power failure cannot be tolerated. The backup power is supplied by a bank of capacitors and since the energy must be supplied for milliseconds to hundreds of milliseconds, high capacitance and voltage is needed (energy is ½CV²). The capacitors of choice for low profile drive applications are Tantalum-Polymer because of their high energy density and low profile surface mount form factor. While general KO-CAP® Tantalum-Polymer capacitors are suitable, the KEMET brand of YAGEO Group also has a dedicated high energy series.
Inductors
Inductors are a key magnetic component used in most high efficiency power supplies. They are available in several form factors and with different core materials. Metal composite inductors consist of an iron alloy powder molded around a copper coil. They are capable of high saturation currents and the inductance rolls off gradually with increasing current. However, the inductor can have significant core loss within the the metal material. Single turn ferrite core inductors or Power Beads have very low losses and are used in many high power applications. The saturation current of ferrites decreases with increasing temperature, and they also have a ‘hard’ saturation where the inductance drops off quickly passed the saturation current limit. An emerging power convertor topology is the Trans-Inductor Voltage Regulator. The TLVR Inductor has two windings and is increasingly being used in high current, high efficiency multi-phase convertors.
What if we could have the best characteristics of metal composite materials and ferrites combined into one material? YAGEO Group has developed such a material–NANOMET® which consists of nanocrystals of iron in an amorphous matrix. The NANOMET® core has loss characteristics approaching that of ferrites while it has the soft saturation characteristics of a metal composite material.
Vertical power delivery–or moving the power convertor directly underneath the chip–is an emerging topology for minimizing power losses by reducing the resistive losses between the power conversion stage and the CPU/GPU. NANOMET® core inductors are an ideal magnetic solution to incorporate into those modules because of their low loss and high saturation current characteristics and commercial modules are already available.
Future Trends
Power delivery solutions for AI applications are continuing to evolve rapidly as power consumed by next generation GPUs will exceed 1000W per processor and each rack will have to be supplied with multiple kilowatts of power. One concern is that the heat generated will no longer be able to be effectively removed by air cooling and either direct liquid cooling of processors via cold plates or cooling by immersion of the entire racks in a dielectric liquid may be needed. If immersion cooling is adopted, then questions about compatibility of components in these dielectric fluids need to be addressed.
Moving the power conversion closer to (or ultimately on) the chip will continue. This means components need to continue to shrink especially in the Z-direction. This is especially important for inductors which are usually the tallest component. This means more modules some of which will be overmolded into a complete System-in-Package (SiP) module. Eventually, the components may be directly attached to the chip or embedded in the circuit board.
At the semiconductor level, technology continues to advance rapidly. Backside power delivery is on the major players roadmap for next generation nodes, and we’ll see how this effects the overall power schemes. The evolution from 2.5D packaging to 3D packaging and to chiplets continues. And, glass interposers are poised to become an addition to or a replacement for silicon interposer technology.
References
- A. de Vries, “The Growing Energy Footprint of Artificial Intelligence,” Joule, 7, 2191 (2023).
- D. Patel, et al., “,” retrieved from: AI Datacenter Energy Dilemma – Race for AI Datacenter Space , March 13, 2024.
- J. Hiller and S. Herra, “Tech Industry Wants to Lock Up Nuclear Power for AI,” Wall Street Journal, July 1, 2024.
- X. Li and S. Jiang, “Google 48V Power Architecture,” APEC, March 27, 2017.
- Y. Elasser, et al., “Circuits and magnetics co‐design for ultra‐thin vertical power delivery: A snapshot review”, MRS Advances, 9, 12–24 (2024).
- Dual phase Power Modules
- Open Compute Project Immersion Requirements
- Soft Magnetic FlakeComposite Material Suitable for Highly Integrated Power Modules

