






Nvidia’s Vera Rubin VR200 NVL72 AI rack uses an estimated 182% more MLCC value than its GB300‑based predecessor, turning multilayer ceramic capacitors into one of the most critical components in the AI server stack.
At the same time, analysts now describe MLCCs as a kind of “new memory” in AI infrastructure, with single racks consuming up to hundreds of thousands of devices and pushing supply close to its limits.
Key takeaways
- Vera Rubin NVL72 increases MLCC value per rack from roughly 1,530 USD to about 4,320 USD—an increase of around 182%.
- High‑end AI racks can require on the order of hundreds of thousands of MLCCs, making MLCCs a top‑three BOM cost item after GPUs and memory.
- AI platforms adopt 48 V distribution, near‑package regulation, and high‑frequency VRMs, all of which push MLCC counts and specifications higher.
- Demand from AI servers is growing far faster than MLCC capacity, creating a structural supply‑demand imbalance that may last several years.
- Power‑integrity co‑design, conservative derating, and footprint standardization for MLCCs are becoming critical disciplines for AI server engineers.
Big picture: AI racks as power‑electronics systems
When we talk about AI hardware, the story usually starts with GPUs and high‑bandwidth memory. Inside racks like Nvidia’s Vera Rubin NVL72, however, there is an equally important power‑electronics story, and multilayer ceramic capacitors sit right at its center.
A Morgan Stanley analysis cited in recent coverage estimates the MLCC content of a Vera Rubin VR200 NVL72 rack at about 4,320 USD, up from roughly 1,530 USD in the earlier GB300 system—an increase of around 182%. Other research notes that a high‑end AI rack can require hundreds of thousands of MLCCs, effectively making MLCCs the third‑largest cost item after GPUs and memory devices.
In parallel, demand from AI servers is expected to grow at very high double‑digit rates from a base of roughly 1+ billion USD, while overall MLCC capacity is forecast to expand much more slowly, setting up a prolonged period of tight supply.
| Metric | Value / Comment |
|---|---|
| Vera Rubin MLCC value per rack | ~4,320 USD |
| GB300 MLCC value per rack | ~1,530 USD |
| Increase in MLCC value per rack | ~182% |
| Typical high‑end AI rack MLCC usage | Up to hundreds of thousands of units per rack |
| AI‑server MLCC demand growth vs overall MLCC | Very high double‑digit CAGR, several times faster than overall MLCC demand |
Recent market reports confirm that this is no longer just a design curiosity but a structural shift in the cost stack of AI infrastructure. In several analyses, MLCCs have quietly moved into the “top three” cost and allocation risk items in AI servers, alongside GPUs and memory, not because of a high unit price but because of the sheer number of capacitors per rack. For PDN design teams, that means MLCC selection has effectively become both an electrical and a strategic sourcing decision.
AI MLCC super‑cycle – engineering implications
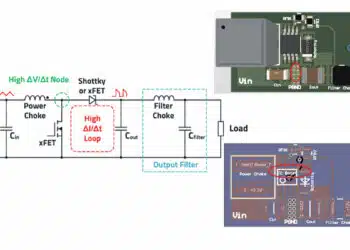
Recent pricing data from distribution and spot markets show selective increases on advanced MLCCs for AI servers, with reported hikes from around 10% up to several‑fold on some high‑capacitance, small‑case, automotive‑ and server‑grade parts. This pattern is concentrated in the same high‑end MLCC classes used around GPU cores and VRM stages in platforms such as GB300 and Vera Rubin, indicating that demand from AI racks is now directly influencing availability and pricing at the board level. Design engineers should therefore assume that MLCC availability, AVL diversity and long‑term price stability are design constraints on the same level as ESR, ESL and thermal performance.
What MLCCs do in an AI rack
Core roles of MLCCs in AI servers.
- Local energy storage around processors
MLCC arrays act as small, very fast energy tanks around GPUs, CPUs, and HBM, absorbing sudden current steps and keeping supply rails within tight voltage limits during fast load changes. - High‑frequency decoupling and impedance shaping
While bulk capacitors and VRMs handle lower‑frequency variations, MLCC networks are tuned to provide low impedance into the hundreds of megahertz range, ensuring stable power‑delivery impedance and VRM control. - Filtering and noise control
Switching regulators, high‑speed SerDes, networking, and control circuits rely on MLCCs in input, output, and snubber networks to suppress conducted and radiated noise across the rack.
As GPU power moves toward the kilowatt range per package in 2026‑class systems, all of these tasks become more demanding, requiring MLCCs with higher voltage ratings, lower ESR, better high‑temperature performance, and stable capacitance under DC bias.
Why Vera Rubin needs so many more capacitors
The 182% increase in MLCC value between Nvidia’s GB300 rack and Vera Rubin NVL72 looks dramatic on paper, but it follows logically from how the architecture has evolved. At the most basic level, Vera Rubin simply packs more “everything” into a single rack: more accelerators, more high‑bandwidth memory stacks, and more high‑speed interconnect, which together drive total rack power substantially higher and multiply the number of distinct power rails that must be carefully decoupled. Every GPU, memory stack, and network chip needs its own tailored capacitor network, so scaling up node count and bandwidth directly translates into more MLCC placements across boards, substrates, and modules.
A second key factor is the shift toward 48 V distribution combined with near‑chip or even in‑package regulation, which is increasingly common in 2026‑class AI platforms. By moving conversion stages closer to the GPU and CPU packages, designers reduce conduction losses and improve overall efficiency, but they also concentrate current transients at the point of load and dramatically tighten the requirements for local decoupling. The immediate surroundings of each processor—substrates, interposers, and power‑module PCBs—must host dense arrays of MLCCs to maintain target impedance and keep supply rails stable when load steps occur. This architectural choice favors higher‑voltage, finer‑pitch ceramic capacitors, often down to 0201 case size or smaller, and drives up both the number of devices and the average value per part.
Finally, Vera Rubin’s power conversion itself is more complex and faster‑switching than in the previous generation. Multi‑phase VRMs, intermediate bus converters, and high‑frequency regulation schemes require carefully tuned capacitor banks for loop stability, transient response, and EMI control. Each added phase, filter section, or snubber network contributes further MLCCs, not just around the main accelerators but also in supporting circuits such as system controllers, timing, and high‑speed I/O. Taken together, more power‑hungry devices, 48 V distribution with near‑chip regulation, and more sophisticated conversion stages explain why Vera Rubin’s MLCC content has jumped so sharply in both quantity and quality compared with GB300.
The result is not just “more parts” but also “better parts”: AI racks demand higher‑voltage, fine‑pitch MLCCs, often down to 0201 case sizes or smaller, with dielectric systems optimized for bias and temperature, which raises both the count and the average value per component.
“MLCC is the new memory”: market and materials
When analysts describe MLCCs as the “new memory” in the AI supply chain, they are not suggesting that capacitors are replacing DRAM or HBM, but rather that MLCCs are entering a similar boom‑and‑bottleneck role in the data‑center ecosystem. Current estimates put the total MLCC market at around 15 billion USD, with AI servers contributing roughly 1.3 billion USD today but expanding at a very high compound growth rate, driven by platforms like Vera Rubin and the broader shift toward accelerator‑rich racks. In this view, MLCCs become a third pillar of AI hardware economics: after GPUs and memory devices, they form the next big line item that can shape both system cost and deployment schedules.
The growth dynamic is made more pronounced by the mismatch between AI‑server demand and high‑end MLCC capacity. Forecasts suggest that AI‑driven MLCC demand will more than quadruple between 2025 and 2030, while total MLCC production capacity grows only modestly above 10% per year. Major MLCC and substrate suppliers report that orders for AI‑grade products are already running far ahead of what current factories can deliver, and that high‑reliability, high‑voltage lines are effectively booked out over multi‑year horizons. In practice, this means AI platforms are competing directly with automotive, industrial, and other high‑end applications for the same advanced ceramic and electrode technologies.
Materials add another layer of complexity. Upstream, the copper supply chain remains tight, with concentrate constraints and elevated prices pushing up the cost base for many power‑electronics and interconnect products. For MLCCs, this affects terminations, internal connections, and the broader ecosystem of boards and power modules they live on. Combined with the structural demand surge from AI servers, these material constraints reinforce the idea that MLCCs are moving into a strategic position, where their availability, performance, and price trajectory can meaningfully influence how fast AI data‑center capacity can grow.
Together, these trends mean that platforms like Vera Rubin not only define compute performance, but also set reference points for MLCC technology, pricing, and availability for several years.
Market note June 2026
The structural MLCC content increase described above is now reflected in manufacturer guidance and lead times. For an overview of how AI demand is driving MLCC pricing and availability, including recent manufacturer commentary on 20‑week‑plus lead times and constraints through 2027, see our 2026 market and MLCC pricing updates.
Design implications for passive component engineers
For design engineers and component specialists, the main lessons are practical and immediate.
- Co‑design power integrity and MLCC networks
In multi‑kilowatt AI racks, power integrity cannot be solved by sprinkling extra MLCCs at the end of the layout. VRM design, package and plane inductance, and MLCC selection and placement need to be treated as a single co‑designed system. - Apply careful derating and verify effective capacitance
Operating at high voltage and temperature with significant DC bias means catalog capacitance values are often not representative. Designers must check effective capacitance under bias, apply conservative voltage and temperature derating, and ensure adequate margins over the platform lifetime. - Standardize case sizes and values where possible
With AI‑grade MLCC supply tight, using standard footprints and value grids improves second‑sourcing options and increases the likelihood of securing volume as platforms ramp. - Track materials and lifecycle early
Copper trends, ceramic capacity, and long platform lifetimes mean that early choices of MLCC families, voltage ratings, and case sizes can effectively lock in the component strategy for many years.
Conclusion
Nvidia’s Vera Rubin NVL72 AI rack, with an estimated 182% increase in MLCC value per rack over its GB300 predecessor, shows how quickly AI architectures are turning multilayer ceramic capacitors into a strategic element of data‑center design.
With rack‑level MLCC counts in the hundreds of thousands and AI‑server demand growing far faster than overall capacity, MLCC technology, power‑integrity engineering, and materials planning are becoming just as important as GPU roadmaps for anyone building or supplying next‑generation AI infrastructure.
Sources / references
- Nvidia’s Vera Rubin uses 182% more capacitors, boosting Samsung Electro‑Mechanics – The Korea Herald
https://www.koreaherald.com/article/10762449 - Copper crunch hits components cost amid AI demand surge – Digitimes
https://www.digitimes.com/news/a20260526PD212/copper-demand-component-2026-materials.html - (Paywalled) coverage on AI‑driven MLCC demand and capacity at major Japanese suppliers – The Japan Times
https://www.japantimes.co.jp/business/2026/05/29/companies/taiyo-yuden-ai-demand/ - Samsung Electro‑Mechanics AI Server Pivot: R&D Surges 36%, Capacity Cannot Match Big‑Tech Demand – TechTimes
https://www.techtimes.com/articles/317337/20260529/samsung-electro-mechanics-ai-server-pivot-rd-surges-36-capacity-cannot-match-big-tech-demand.htm - New breakthrough in the AI supply chain! Goldman Sachs: Multilayer Ceramic Capacitors (MLCC) may be the next memory component – Bitget News
https://www.bitget.com/news/detail/12560605437294 - Global MLCC demand surges as AI servers drive a new cycle in passive components – sector commentary / application notes
http://www.axtekic.com/news/global-mlcc-demand-surges-as-ai-servers-drive-a-new-cycle-in-passive-components.html - MLCC Solutions for Data Center (AI Server) Power Systems – application note
https://product.tdk.com/en/techlibrary/applicationnote/mlcc-solution-for-data-center-psu.html - EPCI AI power electronic components – technical overview of AI‑era power trends
https://www.we-online.com/files/pdf1/epci-ai-power-electronic-components.pdf - How AI Servers Drive MLCC Demand – market‑ and application‑focused note
https://7setronic.com/ai-mlcc-market-demand-ai-servers/